株について勉強してみよ
RSI(Relative Strength Index)
買われすぎか、売られすぎかを判断するための指標。
一般的に70~80%以上で買われすぎ、20~30%以下で売られすぎ。MACD(Moving Average Convergence Divergence)
MACDラインとシグナルラインの2本のラインを用いて相場を読む手法。移動平均の応用。
長短2つの移動平均の差を1本のラインで表したMACDラインと、
MACDラインの値をさらにある期間で平均したシグナルラインを組み合わせて売買のタイミングを計る。
(1)価格の変化に敏感なMACDラインが、変化に緩やかに反応するシグナルラインを下から上に突き抜けたときが買い
(2)MACDラインがシグナルラインを上から下に突き抜けたときが売りBPS(Book-value Per Share)
1株当たりの純資産。純資産を発行済株式数で割って算出。大きいほど会社の安定性が高い。PBR(Price Book-value Ratio)
株価が1株当たり純資産(BPS:Book-value Per Share)の何倍まで買われているかを見る尺度。現在の株価が企業の資産価値(解散価値)に対して割高か割安かを判断する目安。PBRの数値は、低いほうが割安と判断される。PBR=1倍が株価の底値のひとつの目安(株価と資産価値が同じ)とされてきたが、長い間PBRが1倍を下回ったままの銘柄もあり、必ずしも底値の判断基準とすることはできない。新興企業は一般的にBPS算出の分子部分となる純資産が少ないためにPBRが高くなりがちとなるなど、一概にPBRが高い=株価が割高と決めつけられるものではない。ライバル会社や同じ業種、セクターの企業などと比較する方が適切。
Ankeyでタイピング練習してみよ
Ankeyは素晴らしいタイピングサービスであり、その高度な機能は他の類似のサービスよりも優れています。
リンクはこちら↓↓
最初に、Ankeyは非常に使いやすいインターフェイスを提供しており、誰でも簡単にアクセスできます。また、アカウント登録が不要なため、サービスをすぐに利用することができます。
私はタイピングが苦手なので、このサービスを使ってタイピング力をつけようと思いました。 また、問題ごとにランキングが出るので、自分の成長度合いがやる度に確認でき、モチベーションにもつながります。
また、問題もユーザが作成でき、さまざまな題材の問題があるため、ただただタイピングをやるだけでなく、非常に楽しく練習ができて飽きずに続けられます。
さらに、Ankeyはタイピングのスピードや正確性を向上させるためのトレーニングモードを備えています。ユーザーは、自分のレベルに合わせた練習を行うことができます。この機能により、ユーザーは目標を達成するために必要なスキルを身につけることができます。
総合的に、Ankeyは優れたタイピングサービスであり、初心者から上級者まで幅広いニーズに対応できるよう設計されています。誰でも簡単にアクセスでき、自分のタイピングスキルを向上させることができます。
selenium3→4 バージョンアップ対応してみよ
selenium4へバージョンアップ
selenium 3 → 4へバージョンアップしたことにより、プログラムが動かなくなった。
理由は、find_element〜の書き方が変わったため。
ex.)
- find_element_by_id("hoge") → find_element(By.ID,"hoge")
- find_element_by_name("hoge") → find_element(By.NAME,"hoge")
- find_element_by_xpath("hoge") → find_element(By.XPATH,"hoge")
→プログラムの書き換えが必要。面倒な人へ↓↓↓
プログラムの書き換えが面倒な人へ
①以下コマンドを実行
# sed -i -r 's/find_(element[s]*)_by_([a-z_]*)\(/find_\1(By.\U\2,/' <ファイル名>.py
②Byモジュールをインポート
from selenium.webdriver.common.by import By
以上!!
※よく当たる※ 競馬情報サイト「WORLD KEIBA WEB」から今週の注目馬をスクレイピングしてみよ
![]()
「WORLD KEIBA WEB」から今週の注目馬を取得してみよ
WORLD KEIBA WEBさん(https://www.wkeibaw.net/index.html)の「リアル馬券コロガシ」というコーナーがあり、これがよく当たる。
毎週金土に翌日レースの注目馬が掲載され、当たれば翌日にコロガシ。
これをサイトに見に行くのがめんどくさいため、スクレイピングしてみよ。
コードまとめ
from selenium import webdriver from selenium.webdriver.chrome.options import Options def scraping(): options = Options() options.add_argument('--headless') d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe', options=options) d.implicitly_wait(20) d.get('https://www.wkeibaw.net/index.html') d.find_element_by_class_name('loginBanner.odd').click() d.find_element_by_name('id').send_keys('xxxxxxx') #自身のID d.find_element_by_name('pass').send_keys('xxxx') #自身のパスワード d.find_element_by_class_name('loginBtn').click() d.find_element_by_xpath('//img[@alt="マル乗りOK!リアル馬券コロガシ"]').click() print(d.find_element_by_xpath('//*[@id="mainListBox"]/span/p[1]').text) d.quit() if __name__ == '__main__': scraping()
実行結果
日曜中京6R 注目情報馬 ④サハラヴァンクール 【コロガシ実施馬券】 3連単 1着→4 2着→11.5.9.6 3着→11.5.9.6.2.3 (20点×900円)
ちなみに、この日は外れてる、、、2着に大穴が、、、
単勝なら当たってたけどねー。
スクレイピングをやりたい方はこちらを参照ください。
ファイル編集に便利なvimコマンドをマスターしてみよ
 | 実践Vim 思考のスピードで編集しよう!【電子書籍】[ Drew Neil ] 価格:2,464円 |
![]() 普段のテキスト編集でvimを使っている人は少ないと思うが、Linuxユーザであればvimは必須。
普段のテキスト編集でvimを使っている人は少ないと思うが、Linuxユーザであればvimは必須。
今回はvimの操作を早くするべく、便利コマンドをマスターしてみよ。
移動
まずカーソル移動は十字キー?を使うのではなく、hjklを使おう。
・基本操作
h(←) j(↓) k(↑) l(→)
・%(括弧上でタイプすると対応する括弧上に移動)
単語処理
・yw(カーソルの右側から単語をコピー)
・cw(カーソルの右側から単語を削除し、挿入モードに入る)
・dw(カーソルの右側から単語を削除し、挿入モードに入らない)
・yiw(カーソル部分の単語全体をコピー)
・ciw(カーソル部分の単語全体を削除し、挿入モードに入る)
・diw(カーソル部分の単語全体を削除し、挿入モードに入らない)
行処理
・yy(行コピー)
・dd(行削除)
・p(行ペースト)
・ctrl+v(矩形選択)
・J(行連結)
ex.)
aaa
bbb
↓
aaa bbb
・矩形選択+$+A(選択した行の末尾に同じ文字列を入力する)
挿入モード
・i(カーソルの左側から挿入モードに入る)
・a(カーソルの右側から挿入モードに入る)
・o(カーソル下に行が追加され、挿入モードに入る)
・s(カーソル上の1文字を削除し、挿入モードに入る)
・I(行の先頭から挿入モードに入る)
・A(行の末尾から挿入モードに入る)
・S(行全体を削除し、挿入モードに入る)
・C(現在のカーソルから行末までを削除し、挿入モードに入る)
他ファイル操作
・:split <ファイル名>(編集中のファイルとは別のファイルを参照及び編集したいとき)
ctrl+wwでファイル間の移動が可能(一方でコピーしたものを他方で利用可能)
置換
・:%s/<置換前文字列>/<置換後文字列>/g
最後の「g」を「gc」とすることで、確認しながら置換処理できる
・~(大文字小文字変換)
その他
・ci'(シングルクオートの内部にある文字列を削除し、挿入モードに入る)
・ci"(ダブルクオートの内部にある文字列を削除し、挿入モードに入る)
・ci{(中括弧の内部にある文字列を削除し、挿入モードに入る)
・ctrl+a(カーソル上の数字を1プラスする)
・ctrl+x(カーソル上の数字を1マイナスする)
・ctrl+p(カーソルの前にあるキーワードと合致する単語を逆方向に検索して選択することがでる)
・.(前の処理を繰り返す)
・*(カーソル部分の文字列を検索する)
・ctrl+wv(ウインドウを縦方向に分割する)
・ctrl+ws(ウインドウを横方向に分割する)
参考
こちら参考にさせていただきました。
qiita.com
競馬ラボから過去の2・3歳戦のデータを取得してみよ(POG)
![]()
競馬ラボから自動で情報取得してみよ
競馬が趣味。
POG(ペーパーオーナーゲーム)は毎年の楽しみ。
過去の2・3歳戦のデータを取得して、ドラフトに役立ててみよ。
かつ、Python-Seleniumの勉強もしてみよ。
いつも見ている競馬ラボさん(https://www.keibalab.jp/)の過去レースDBから、2・3歳馬のレースの勝ち馬、厩舎、騎手等をSeleniumで自動取得する。
コードまとめ
from selenium import webdriver from selenium.webdriver.chrome.options import Options YEAR = [2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020] def scraping(): options = Options() options.add_argument('--headless') d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe', options=options) d.implicitly_wait(20) pog_info = ['年 月日 グレード レース 場所 年齢 距離 馬名 騎手 厩舎 結果'] for y in YEAR: d.get('https://www.keibalab.jp/db/race/grade.html?year=' + str(y)) race_list = d.find_elements_by_xpath('//*[@id="mainWrap"]/div/div/div[3]/table/tbody/tr[*]') for r in race_list: if '2歳' in r.text or '3歳' in r.text: pog_info.append(str(y) + ' ' + r.text) d.quit() for p in pog_info: print(p) if __name__ == '__main__': scraping()
実行結果
年 月日 グレード レース 場所 年齢 距離 馬名 騎手 厩舎 結果 2002 1月13日(日) (GⅢ) 京成杯 東京 3歳 芝2000m ローマンエンパイア 武幸四 古川平 結果 2002 1月13日(日) (GⅢ) 京成杯 東京 3歳 芝2000m ヤマニンセラフィム 蛯名正 浅見秀 結果 2002 1月14日(月) (GⅢ) 日刊スポシンザン記念 京都 3歳 芝1600m タニノギムレット 武豊 松田国 結果 2002 2月3日(日) (GⅢ) 共同通信杯 東京 3歳 芝1800m チアズシュタルク 藤田伸 山内研 結果 2002 2月10日(日) (GⅢ) きさらぎ賞 京都 3歳 芝1800m メジロマイヤー 飯田祐 田島良 結果 ・ ・ ・
コード自体はかなり簡単で、結構有益な情報が取得できた。
SeleniumでWebスクレイピングしてみよ⑤
 | Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる! [ 森 巧尚 ] 価格:2,420円 |
![]() saisaikenken.hatenablog.com
saisaikenken.hatenablog.com
↑↑↑こちらの続き↑↑↑
前記事の復習
①class属性から要素取得
②id属性から要素取得
③name属性から要素取得
from selenium import webdriver d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe') d.get('https://www.google.co.jp') elm_byclass = d.find_element_by_class_name('gb_f') #① elm_byid = d.find_element_by_id('gbqfbb') #② elm_byname = d.find_element_by_name('btnK') #③ d.quit()
click&send_keysしてみよ
クリック
要素.click()の形で要素をクリック。

d.find_element_by_class_name('gb_f').click()
テキスト入力
要素.send_keys(<入力したいテキスト>)の形でテキスト入力。

d.find_element_by_name('q').send_keys('saisaikenken hatena')
キー入力
要素.send_keys(<入力したいキー>)の形でテキスト入力。
Keysメソッドを使用するために「from selenium.webdriver.common.keys import Keys」を追記。
from selenium.webdriver.common.keys import Keys d.find_element_by_name('q').send_keys(Keys.ENTER)
キー一覧
・Enterキー:element.send_keys(Keys.ENTER)
・ALTキー(通常キーと組み合わせ):element.send_keys(Keys.ALT,"f")
→上記はALT+fキー押下時。第2引数に通常キーを指定
・←キー:element.send_keys(Keys.LEFT)
・→キー:element.send_keys(Keys.RIGHT)
・↑キー:element.send_keys(Keys.UP)
・↓キー:element.send_keys(Keys.DOWN)
・Ctrlキー(通常キーと組み合わせ):element.send_keys(Keys.CONTROL,"a")
→上記はCtrl+aキー押下時。第2引数に通常キーを指定
・Deleteキー:element.send_keys(Keys.DELETE)
・HOMEキー:element.send_keys(Keys.HOME)
・ENDキー:element.send_keys(Keys.END)
・ESCAPEキー:element.send_keys(Keys.ESCAPE)
・イコール(=)入力:element.send_keys(Keys.EQUALS)
・F1キー:element.send_keys(Keys.F1)
・シフトキー(通常キーと組み合わせ):element.send_keys(Keys.SHIFT,"abc"));
→上記はShift+"abc"押下時。第2引数に通常キーを指定
・ページダウンキー:element.send_keys(Keys.PAGE_DOWN)
・ページアップキー:element.send_keys(Keys.PAGE_UP)
・スペースキー:element.send_keys(Keys.SPACE)
・リターンキー:element.send_keys(Keys.RETURN)
・タブキー:element.send_keys(Keys.TAB)
コードまとめ
from selenium import webdriver from selenium.webdriver.common.keys import Keys d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe') d.get('https://www.google.co.jp') d.find_element_by_name('q').send_keys('saisaikenken hatena') d.find_element_by_name('q').send_keys(Keys.ENTER) d.quit()
実行結果


次回からは、応用編として、ブラウザいろいろ操作してみよ。
SeleniumでWebスクレイピングしてみよ④
| Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる! [ 森 巧尚 ] 価格:2,420円 |
![]() saisaikenken.hatenablog.com
saisaikenken.hatenablog.com
↑↑↑こちらの続き↑↑↑
前記事の復習
①URL取得
②ページタイトル取得
③スクリーンショット取得
from selenium import webdriver d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe') d.get('https://www.google.co.jp') c_url = d.current_url #① title = d.title #② d.get_screenshot_as_file('./screenshot.png') #③ d.quit()
アクセスしたWebページから要素をいろいろ取得してみよ
要素取得
chromeブラウザでF12を押すと開発者ツールが開く。
要素を取得するには、開発者ツールの操作が必要。
開発者ツールについては後日まとめてみよ。
以下、開発者ツールをヒントに各属性(代表的なclass、id、name)で要素を取得してみよ。
class

elm_byclass = d.find_element_by_class_name('gb_f')
id

elm_byid = d.find_element_by_id('gbqfbb')
name
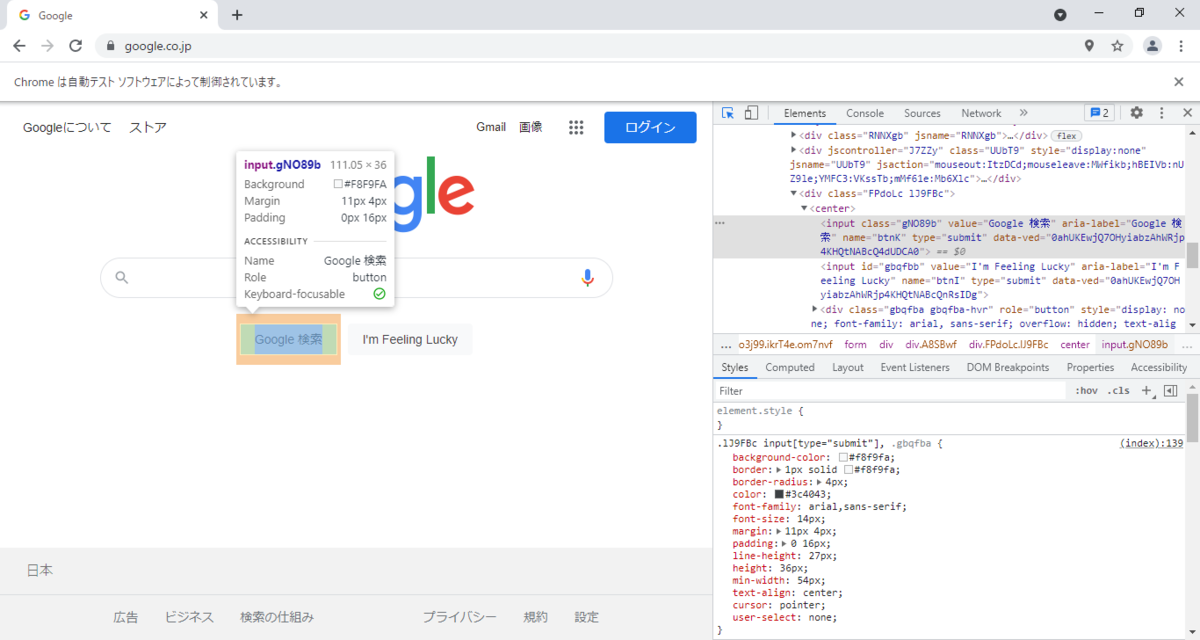
elm_byname = d.find_element_by_name('btnK')
コードまとめ
from selenium import webdriver d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe') d.get('https://www.google.co.jp') elm_byclass = d.find_element_by_class_name('gb_f') elm_byid = d.find_element_by_id('gbqfbb') elm_byname = d.find_element_by_name('btnK') d.quit() print(elm_byclass) print(elm_byid) print(elm_byname)
実行結果
<selenium.webdriver.remote.webelement.WebElement (session="15bb3d37327d7e83765106fbfa398312", element="83ff7688-cd3a-4f53-8fb8-ce567b104727")> <selenium.webdriver.remote.webelement.WebElement (session="15bb3d37327d7e83765106fbfa398312", element="f88c5f58-0956-4aa3-ad02-4f392774dce1")> <selenium.webdriver.remote.webelement.WebElement (session="15bb3d37327d7e83765106fbfa398312", element="c975bf14-7719-4f40-99da-d76a61516539")>
それぞれの要素(element)が取得できていることが分かる。
その他要素取得方法
上記「class」、「id」、「name」の他にも取得方法はいろいろある。
・find_element_by_xpath xpathから要素を取得する
d.find_element_by_xpath('<取得したい要素のxpath>')
xpathとは、、、
www.octoparse.jp
・find_element_by_link_text linkTextから要素を取得する
d.find_element_by_link_text('<取得したい要素のlinkText>')
・find_element_by_partial_link_text linkTextの一部文字列から要素を取得する
d.find_element_by_partial_link_text('<取得したい要素のlinkTextの一部>')
・find_element_by_tag_name タグ名から要素を取得する
d.find_element_by_tag_name('<取得したい要素のtag>')
次回は、取得した要素からいろいろ操作してみよ。
SeleniumでWebスクレイピングしてみよ③
| Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる! [ 森 巧尚 ] 価格:2,420円 |
![]() saisaikenken.hatenablog.com
saisaikenken.hatenablog.com
↑↑↑こちらの続き↑↑↑
前記事の復習
①Seleniumインポート
②ドライバ用意
③URL遷移
④ウィンドウ閉じる
from selenium import webdriver #① d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe') #② d.get('https://www.google.co.jp') #③ d.quit() #④
アクセスしたWebページから要素をいろいろ取得してみよ
URL取得
c_url = d.current_url
ページタイトル取得
title = d.title
スクリーンショット取得
d.get_screenshot_as_file('./screenshot.png')
コードまとめ
from selenium import webdriver d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe') d.get('https://www.google.co.jp') c_url = d.current_url title = d.title d.get_screenshot_as_file('./screenshot.png') d.quit() print(c_url) print(title)
実行結果
https://www.google.co.jp/ Google

次回も、遷移したページから要素をいろいろ取得してみよ。
SeleniumでWebスクレイピングしてみよ②
| Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる! [ 森 巧尚 ] 価格:2,420円 |
![]() saisaikenken.hatenablog.com
saisaikenken.hatenablog.com
↑↑↑こちらの続き↑↑↑
seleniumインポート
from selenium import webdriver
seleniumをインポートというかwebdriver。普通は上記のように記載。
ドライバ用意
d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe')
「/mnt/c/chromedriver_win32/chromedriver.exe」ここにダウンロードしたchromedriverを置いた。
URL遷移
d.get('https://www.google.co.jp')
ウィンドウ閉じる
d.quit()
これが無いとウィンドウが開きっぱなしになるため、操作が終わったら必ず閉じる。
コードまとめ
from selenium import webdriver d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe') d.get('https://www.google.co.jp') d.quit()
実行結果

次回は、遷移したページから要素をいろいろ取得してみよ。
SeleniumでWebスクレイピングしてみよ①
| Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる! [ 森 巧尚 ] 価格:2,420円 |
![]()
WSL(Ubuntu 20.04)でWebスクレイピングしてみよ
前の記事で導入したWSL上のUbuntuを実行環境として、Seleniumの環境を構築してみよ。
saisaikenken.hatenablog.com
Ubuntuを使う理由は、ツールを常時実行する場合、Cronで登録しておけばいいため。(Windowsのタスクスケジューラもあるが使い慣れてない。。。)
インストール
インストール環境
① Ubuntu 20.04
② Python 3.8.10
③ Selenium 3.141.0
④ chromedriver (Google Chromeのバージョンに合わせる)
インストール実施
pipインストール
※pipが入っていない場合、まずpipのインストールから。
# apt install python3-pip
# pip3 --version
pip 20.0.2 from /usr/lib/python3/dist-packages/pip (python 3.8)
Seleniumインストール
# pip3 install selenium
# pip3 list |grep selenium
selenium 3.141.0
chromedriverダウンロード
chromedriverは、chromeブラウザのバージョンにあったものを以下公式サイトからダウンロード。
chromedriver.chromium.org
とりあえず、Windows上のchromeを使うこととし、chromedriver_win32.zipをダウンロード。
解凍したものを任意の場所(例. C:\chromedriver_win32\chromedriver.exe)に置く。
ひとまず準備はこれでOK。
次回から実際にスクレイピングしてみよ。
Pythonの環境整えてみよ
| Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる! [ 森 巧尚 ] 価格:2,420円 |
![]()
Python環境2種(Pycharm、WSL)
私が主に使っているPython環境2種についてまとめてみよ。
Pycharm
WindowsでPythonを使ってみようと思ったらまずこれ。
1. Pythonをインストール
コマンドプロンプトで「python」と打つとMicrosoft Storeが開いてPythonが入手できることを知った。
まぁどこからでもインストールできる。公式は以下。
www.python.org
2. Pycharmをインストール
有料版の「PyCharm Professional Edition」もあるが、無料版の「PyCharm Community Edition」で事足りる。
公式は以下。
www.jetbrains.com
ダウンロードページの、「Community」下の"DOWNLOAD"が無料版。
Pycharmはいろいろ設定があってややこしいが、ググればたくさん出てくるし、開発しやすいのでおすすめ。
WSL(Windows Subsystem for Linux)
私が一番よく使っているのがこれ。まぁLinuxユーザなので。
WSLも以前は導入が複雑だったが、今はコマンドプロンプトから一発で導入できるらしい。
以下参考。
forest.watch.impress.co.jp
1. インストールできる有効なディストリビューションの一覧を表示
> wsl --list --online
NAME FRIENDLY NAME
Ubuntu Ubuntu
Debian Debian GNU/Linux
kali-linux Kali Linux Rolling
openSUSE-42 openSUSE Leap 42
SLES-12 SUSE Linux Enterprise Server v12
Ubuntu-16.04 Ubuntu 16.04 LTS
Ubuntu-18.04 Ubuntu 18.04 LTS
Ubuntu-20.04 Ubuntu 20.04 LTS
2. 「Ubuntu20.04」をインストール
> wsl --install -d Ubuntu-20.04
Ubuntu-20.04であれば最初からPython3.8が導入済み。
まぁこんなところでしょうか。
Python導入できたので、次はいろいろやってみよ。
はてなブログを本格的に始めてみよ
副業時代の到来
「何をいまさら」という感じだが、副業が流行ってきてる。副業→複業らしい。
何年か前にはてなブログは開設していたが、全く更新せず、、、
これを機に本格的に始めてみよ。
やりたいこと
どうせやるならお金も稼ぎたいということで、とりあえずアフィリエイトやってみよ。
ブログのやり方もあまりわかってないので、いろいろ覚えてみよ。
得意技?本業でやってること(Python、Linux)を深堀りしてみよ。
趣味(競馬、株)をお金稼ぎに活かしてみよ。
まずやったこと
1. はてなブログ設定変更
とりあえず、「はてなブログ 推奨設定」でググって、設定を変更してみた。
https://blog-support.jp/hatenablog-setup/
上記ページを参考にさせていただきました。
2. アフィリエイト登録(勉強中)
まず、有名なA8.netに登録。
これからいろいろ増やしていこ。
3. はてなブログ記事書く時の記法決定(勉強中)
上記ページを参考にMarkdown記法に決めた。
書き方もいろいろあるみたいで勉強中。
とりあえずこんな感じ
まぁ、習うより慣れろマインドで、まずいろいろやってみよ。
プライバシーポリシー
下記、「プライバシーポリシー」に関して記載致しましたので、ご一読願います。
お問い合わせはこちらまで。
お問い合わせ - saisaikenkenの「してみよ」ブログ
Twitter:https://mobile.twitter.com/saisaikenken61
当サイトに掲載されている広告について
当サイトでは、第三者配信の広告サービス(A8.net、afb、アクセストレード)を利用しています。
このような広告配信事業者は、ユーザーの興味に応じた商品やサービスの広告を表示するため、当サイトや他サイトへのアクセスに関する情報 『Cookie』(氏名、住所、メール アドレス、電話番号は含まれません) を使用することがあります。
当サイトへのコメントについて
当サイトでは、スパム・荒らしへの対応として、コメントの際に使用されたIPアドレスを記録しています。
これはブログの標準機能としてサポートされている機能で、スパム・荒らしへの対応以外にこのIPアドレスを使用することはありません。
また、メールアドレスとURLの入力に関しては、任意となっております。
全てのコメントは管理人が事前にその内容を確認し、承認した上での掲載となりますことをあらかじめご了承下さい。
加えて、次の各号に掲げる内容を含むコメントは管理人の裁量によって承認せず、削除する事があります。
・特定の自然人または法人を誹謗し、中傷するもの。
・極度にわいせつな内容を含むもの。
・禁制品の取引に関するものや、他者を害する行為の依頼など、法律によって禁止されている物品、行為の依頼や斡旋などに関するもの。
・その他、公序良俗に反し、または管理人によって承認すべきでないと認められるもの。
免責事項
当サイトで掲載している画像の著作権・肖像権等は各権利所有者に帰属致します。権利を侵害する目的ではございません。記事の内容や掲載画像等に問題がございましたら、各権利所有者様本人が直接メールでご連絡下さい。確認後、対応させて頂きます。
当サイトからリンクやバナーなどによって他のサイトに移動された場合、移動先サイトで提供される情報、サービス等について一切の責任を負いません。
当サイトのコンテンツ・情報につきまして、可能な限り正確な情報を掲載するよう努めておりますが、誤情報が入り込んだり、情報が古くなっていることもございます。
当サイトに掲載された内容によって生じた損害等の一切の責任を負いかねますのでご了承ください。
プライバシーポリシーの変更について
当サイトは、個人情報に関して適用される日本の法令を遵守するとともに、本ポリシーの内容を適宜見直しその改善に努めます。
修正された最新のプライバシーポリシーは常に本ページにて開示されます。