SeleniumでWebスクレイピングしてみよ④
 | Python2年生 スクレイピングのしくみ 体験してわかる!会話でまなべる! [ 森 巧尚 ] 価格:2,420円 |
![]() saisaikenken.hatenablog.com
saisaikenken.hatenablog.com
↑↑↑こちらの続き↑↑↑
前記事の復習
①URL取得
②ページタイトル取得
③スクリーンショット取得
from selenium import webdriver d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe') d.get('https://www.google.co.jp') c_url = d.current_url #① title = d.title #② d.get_screenshot_as_file('./screenshot.png') #③ d.quit()
アクセスしたWebページから要素をいろいろ取得してみよ
要素取得
chromeブラウザでF12を押すと開発者ツールが開く。
要素を取得するには、開発者ツールの操作が必要。
開発者ツールについては後日まとめてみよ。
以下、開発者ツールをヒントに各属性(代表的なclass、id、name)で要素を取得してみよ。
class

elm_byclass = d.find_element_by_class_name('gb_f')
id

elm_byid = d.find_element_by_id('gbqfbb')
name
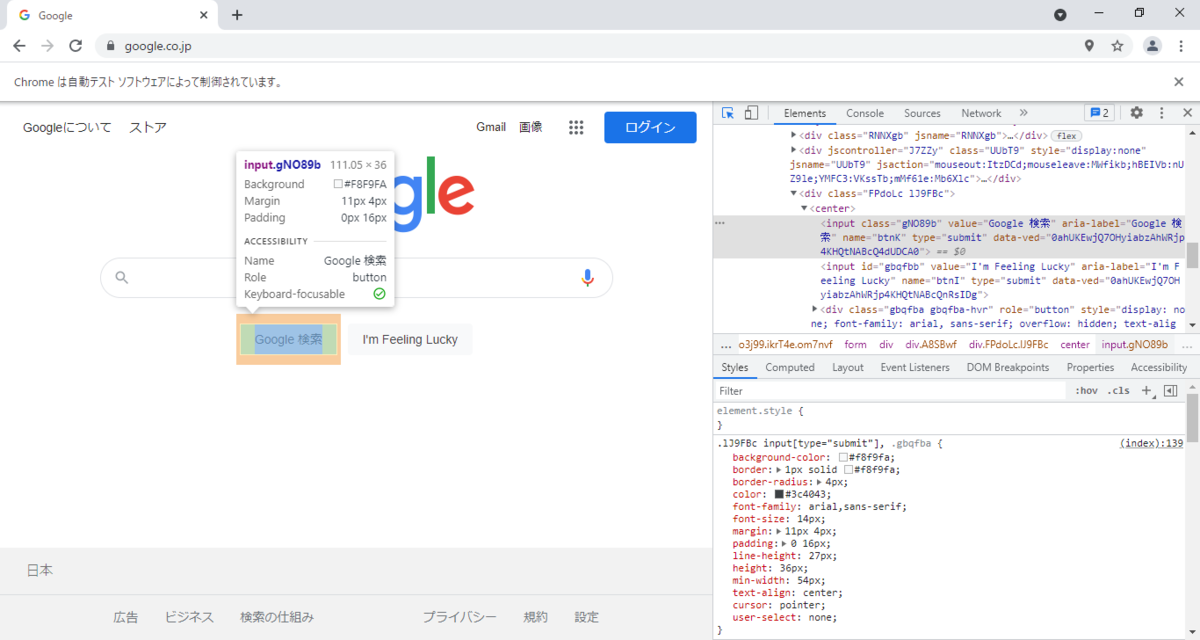
elm_byname = d.find_element_by_name('btnK')
コードまとめ
from selenium import webdriver d = webdriver.Chrome(executable_path='/mnt/c/chromedriver_win32/chromedriver.exe') d.get('https://www.google.co.jp') elm_byclass = d.find_element_by_class_name('gb_f') elm_byid = d.find_element_by_id('gbqfbb') elm_byname = d.find_element_by_name('btnK') d.quit() print(elm_byclass) print(elm_byid) print(elm_byname)
実行結果
<selenium.webdriver.remote.webelement.WebElement (session="15bb3d37327d7e83765106fbfa398312", element="83ff7688-cd3a-4f53-8fb8-ce567b104727")> <selenium.webdriver.remote.webelement.WebElement (session="15bb3d37327d7e83765106fbfa398312", element="f88c5f58-0956-4aa3-ad02-4f392774dce1")> <selenium.webdriver.remote.webelement.WebElement (session="15bb3d37327d7e83765106fbfa398312", element="c975bf14-7719-4f40-99da-d76a61516539")>
それぞれの要素(element)が取得できていることが分かる。
その他要素取得方法
上記「class」、「id」、「name」の他にも取得方法はいろいろある。
・find_element_by_xpath xpathから要素を取得する
d.find_element_by_xpath('<取得したい要素のxpath>')
xpathとは、、、
www.octoparse.jp
・find_element_by_link_text linkTextから要素を取得する
d.find_element_by_link_text('<取得したい要素のlinkText>')
・find_element_by_partial_link_text linkTextの一部文字列から要素を取得する
d.find_element_by_partial_link_text('<取得したい要素のlinkTextの一部>')
・find_element_by_tag_name タグ名から要素を取得する
d.find_element_by_tag_name('<取得したい要素のtag>')
次回は、取得した要素からいろいろ操作してみよ。